Title here
Summary here
iRODS stands for integrated Rule-Oriented Data System iRODS and is an Open Source Data Management software. The ZDV provides an iRODS-system to meet modern data management requirements, in particular:
If you would like to know more about the internal workings, take a look on a more detailed description.
iRODS renamed the PAM authentication. Therefore, you must change the authentication method to pam_password in your .irods/irods_environment.json file:
sed -e 's/"PAM"/pam_password/' -i .irods/irods_environment.jsonor, if you want to do it manually, replace the line "irods_authentication_scheme": "PAM", by "irods_authentication_scheme": "pam_password",
After changing the irods_environment.json file use iinit.
If you want to store a lot of data (several GB), we recommend to zip/tar it to files between 5 and 200GB. If you want to store single files larger than 200GB, please contact the in advance.
There is no need to apply for an iRODS archiving account. Every user of our HPC resources automatically gets access to iRODS. If your account is associated with a MOGON project you also get read/write access to the iRODS project collection (/zdv/project/<PROJECT NAME> ). iRODS collections start with /zdv, whereas paths on the MOGON-filesystem do not have this /zdv-prefix part in their path.
The auto-generated configuration is stored in a users home directory. Here, you can get more detailed information.
Subcollections in the home collection of an individual user will be deleted once the account gets deleted. Only the /zdv/project/<PROJECT NAME> collections will be archived for an appropriate period (default: 10 years, as suggested by the
DFG, Leitlinie 17
).
The data saved to the above project collection is owned by the group. This means after a user leaves the project, the data can still be accessed by the other group members, as long as the access permissions are not modified.
Important: Before you start
Since the HPC system uses its own identity management via SSH-keys, you need to identify yourself against the central system. For this you run
iinit # to create a temporary ticketwhich will prompt you for your password - this is the password associated with your account, rather then the passphrase associated with your ssh-keys or anything else.
Here is a short summary over the most important iRODS commands with some important command line parameters. All commands from the iRODS command line tools start with an i and they are installed on the Mogon login nodes.
iRODS works based a kind of a virtual file system#storage_locations. The following commands can be used to for navigation and are analogous to their bash-counterparts without the i-prefix.
| Command | Parameters | Description |
|---|---|---|
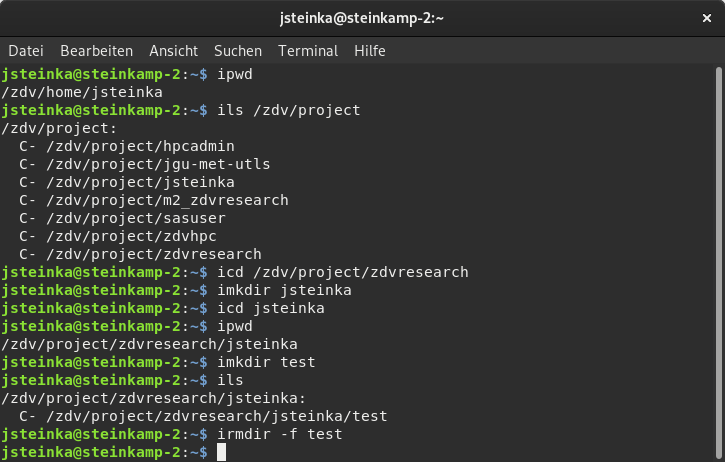
ipwd | print current iRODS working directory (collection) | |
ils | -l, -L, -A | list iRODS collection (-l: with details; -L: more details; -A: ACL) |
icd | <target path> | change iRODS collection |
imkdir | -p <coll> | create a new collection (directory; -p: with parents) |
Each user gets a personal home under /zdv/home/${USER} and access to the associated HPC projects under /zdv/project/<PROJECT NAME>.
Accessible collections:
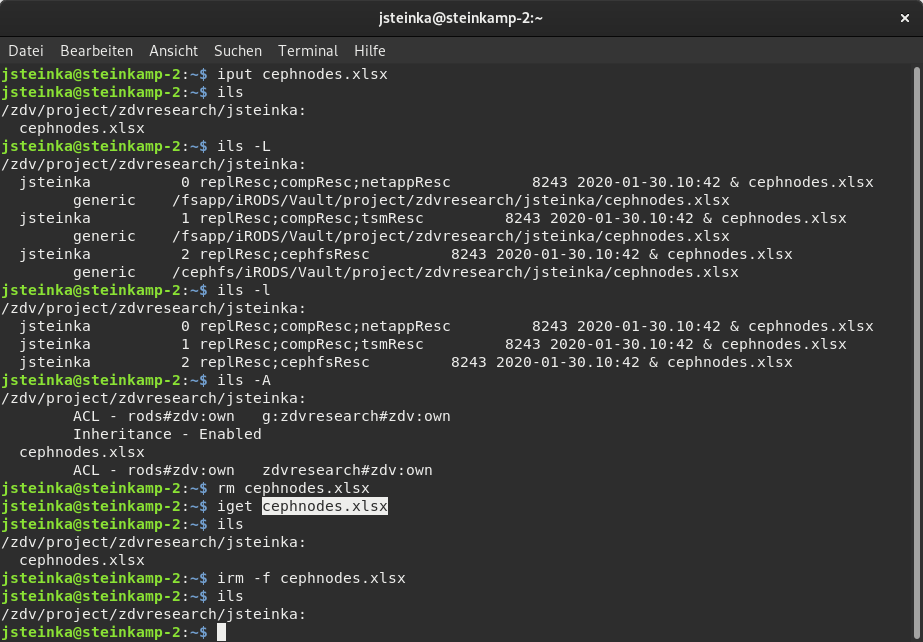
/zdv/home/${USER} private directory/zdv/project/<PROJECT NAME> project directory/zdv/home/public every registered user can read/write/delete/zdv/trash/home/${USER} private trash binUploading data to the iRODS-Archive is done with the command iput.
| Command | Parameters | Description |
|---|---|---|
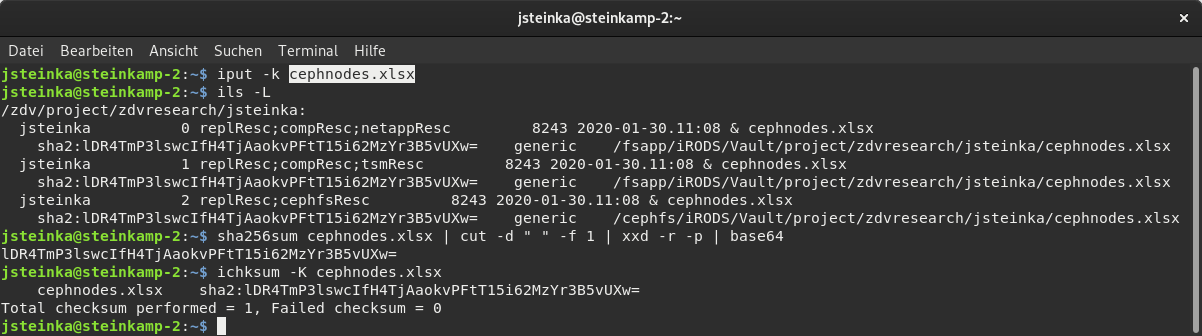
iput | -K, -k, -r | Upload files/directories, ( -k: calculate checksums; -K: calculate checksums and validate; -r: recursively work upon directories) |
ichksum | -r <obj|coll> | Compute and store checksums (-r: recursive) |
The checksum is calculated on the iRODS server and we highly recommend to switch it on immediately on upload. Nevertheless, You can also do it later on with ichksum -K <filename>. It creates a checksum equivalent to the command sha256sum <local filename> | cut -d ' ' -f 1 | xxd -r -p | base64, which you can compare to ensure data integrity. The checksums can be queried with ils -L.
Hint: Bundle before Archiving
Prior to archiving several small files, e.g. files in a directory, they should be bundled. Here is a description how to compress many files in parallel.
It is possible to make up for the forgotten bundling using the ibun command, e.g. to bundle a given iRODS collection called mydir into a tar file:
ibun -cDtar mydir1.tar mydiriRODS allows for fine-grained access control. You can use the ichmod command to grant or withdraw permissions with the following parameters:
| Parameter | Description |
|---|---|
null|read|write|own | access right |
User|Group | to whom |
Object|Collection | for what |
-r is a useful optional parameter for recursive ACL modifications. Also, see the chmod bash manual (man chmod) for comparison.
To get data from the iRODS archive, the iget command can be used:
| Parameter | Description |
|---|---|
-r | recursive for a collection |
-f | overwrite local existing files |
We provide an example page with all the used commands, so far.
Metadata, describing the archived data, are of great importance when striving for reproducible research. Only sufficient metadata describing creation and content of data will ensure a reliable lookup, if need arises.
In iRODS metadata are defined as so called AVU triplets (Attribute, Value, Unit). The first two fields (AV) are mandatory and must not be empty, the unit (U) is optional. AV are defined as VARCHAR(2700) and U as VARCHAR(250), which means they are all text with a maximum size of 2700 and 250 characters, respectively. They might also contain JSON, XML or YAML as text.
| Parameter | Description |
|---|---|
add|set|rm|ls|cp | command, see next table for details (ls|cp do not require the AVU triplet) |
-d dataObject|-C collection | which object/collection (file/path) should be queried/edited |
Attribute Value [Unit] | AVU triplet, where the Unit is optional |
Command Description:
| Command | Description |
|---|---|
add | add a AV(U) triplet |
set | set a single value |
rm | remove an AV(U) triplet |
ls | list existing metadata. If Attribute is given, only metadata of the given attribute |
cp | copy existing metadata. Needs a target and source (e.g. imeta cp -d source -c target) |
The following command lists the metadata automatically associated with the previously upladed file hello_world.txt:
imeta ls -d hello_world.txtThe output of the query is:
AVUs defined for dataObj hello_world.txt:
attribute: AccessRights
value: closed
units:
----
attribute: Creator
value: Steinkamp, J.
units:
----
attribute: Date
value: 1566206896
units:
----
attribute: ExpiryDate
value: 1882430896
units:
----
attribute: Location
value: Mainz, Germany
units:
----
attribute: protected
value: false
units:
----
attribute: Publisher
value: Johannes Gutenberg-University
units:
[user@login01 ~]$You can now add a title, which is not created automatically:
imeta set -d hello_world.txt Title "Archive of experimental szstem from '$(date)'"If you query the Attribute ‘Table’ with imeta ls -d hello_world.txt Title you get:
AVUs defined for dataObj hello_world.txt:
attribute: Title
value: Archive of experimental szstem from 'Mon Aug 19 11:39:48 CEST 2019'
units:Adjusting Meta Data
In the example we deliberately made an error (you might have noticed). You can correct such glitches with the general syntax:
imeta mod -d <filename> <attribute> <old value> v:<new value>or in our example:
imeta mod -d hello_world.txt Title "Archive of experimental szstem from 'Mon Aug 19 11:39:48 CEST 2019'" v:"Archive of experimental system from 'Mon Aug 19 11:39:48 CEST 2019'"For further details see man imeta.
Some meta data attributes are set automatically, to meet most meta data minimum standards (see our policies), those are:
Set automatically:
User input required:
Write Protection
There is one attribute, which should be used with caution: protected (which default value is ‘false’). If the attribute protected with the value true is set (case sensitive!) or modified to true, the user cannot delete/overwrite the object and most of the metadata attributes any more. This is for the case, if data integrity needs to be ensured, that p.e. after a publication the data cannot be changed any more. Nevertheless, additional metadata attributes can still be edited.
If the dataset should be FAIR (Findable, Accessible, Interaperable, Reusable), these attributes are also mandatory:
Further fields can be inserted. This depends on the scientific field and is the responsibility of the respective researcher or group.
Aside of the iRODS commands for editing metadata, contemporary scientific datamanagement adapts more and more data schemas to annotate data sets of various kinds. We therefore provide a helper script.
ilocate[user@login01 ~]$ ilocate -t "hello_world.txt"
/zdv/home/user/hello_world.txt
/zdv/home/public/hello_world.txtimeta quYou must know, if you want to search for a data object (-d) or a collection (-C). And you can use SQL wildcards (%), if you don’t know the exact pattern you are looking for. The wildcard pattern matching is also applicable for ilocate.
[user@login01 ~]$ imeta qu -d Title like "Archive%"
collection: /zdv/home/user
dataObj: hello_world.txtiquestFor this complex syntax consult the Online help .
For public access a ticket needs to be created for collections or data objects. For example, if you use the above uploaded hello_world.txt file again.
[user@login01 ~]$ iticket create read hello_world.txt
ticket:ACR2RKDyuZMBRmbWith this ticket and the path everybody can query information and the content of collections and data objects vi a provided REST-API. JSON strings are returned for valid URLs.
[user@login01 ~]$ curl https://irods-web.zdv.uni-mainz.de/irods-rest/rest/dataObject/zdv/home/jsteinka/hello_world.txt?ticket=ACR2RKDyuZMBRmb{"id":1808764,
"collectionId":24346,
"dataName":"hello_world.txt",
"collectionName":"/zdv/home/jsteinka",
"dataReplicationNumber":0,
"dataVersion":0,
"dataTypeName":"generic",
"dataSize":24,
"resourceGroupName":"",
"resourceName":"netappResc",
"dataPath":"/fsapp/iRODS/Vault/home/jsteinka/hello_world.txt",
"dataOwnerName":"jsteinka",
"dataOwnerZone":"zdv",
"replicationStatus":"1",
"dataStatus":"",
"checksum":"sha2:XPdR4XQP49lWUGEfPJz0Jo+kmkndGxz6rCQUzCqHteA=",
"expiry":"00000000000",
"dataMapId":0,
"comments":"",
"createdAt":1566206868000,
"updatedAt":1566206868000,
"specColType":"NORMAL",
"objectPath":""
}[user@login01 ~]$ curl https://irods-web.zdv.uni-mainz.de/irods-rest/rest/dataObject/zdv/home/jsteinka/hello_world.txt/metadata?ticket=ACR2RKDyuZMBRmb{"metadataEntries": [
{"count":1,
"lastResult":true,
"totalRecords":0,
"attribute":"AccessRights",
"value":"closed",
"unit":""},
{"count":2,
"lastResult":true,
"totalRecords":0,
"attribute":"Publisher",
"value":"Johannes Gutenberg-University",
"unit":""},
{"count":3,
"lastResult":true,
"totalRecords":0,
"attribute":"Location",
"value":"Mainz, Germany",
"unit":""},
{"count":4,
"lastResult":true,
"totalRecords":0,
"attribute":"protected",
"value":"false",
"unit":""},
{"count":5,
"lastResult":true,
"totalRecords":0,
"attribute":"Creator",
"value":"Steinkamp, J.",
"unit":""},
{"count":6,
"lastResult":true,
"totalRecords":0,
"attribute":"Date",
"value":"1566206896",
"unit":""},
{"count":7,
"lastResult":true,"
totalRecords":0,
"attribute":"ExpiryDate",
"value":"1882430896",
"unit":""},
{"count":8,
"lastResult":true,
"totalRecords":0,
"attribute":"Title",
"value":"Archive of experimental system from 'Mon Aug 19 11:39:48 CEST 2019'",
"unit":""}],
"objectType":"DATA_OBJECT","uniqueNameString":"/zdv/home/jsteinka/hello_world.txt"}The file content can be viewed with curl or downloaded with wget.
curl https://irods-web.zdv.uni-mainz.de/irods-rest/rest/fileContents/zdv/home/jsteinka/hello_world.txt?ticket=ACR2RKDyuZMBRmbcurl https://irods-web.zdv.uni-mainz.de/irods-rest/rest/collection/zdv/home/public/helloCollection?ticket=mbyAAFGm7vhUdyM{
"collectionId":1808781,
"collectionName":"/zdv/home/public/helloCollection",
"objectPath":"",
"collectionParentName":"/zdv/home/public/",
"collectionOwnerName":"rods",
"collectionOwnerZone":"zdv",
"collectionMapId":"0",
"collectionInheritance":"",
"comments":"",
"info1":"",
"info2":"",
"createdAt":1566213731000,
"modifiedAt":1566213731000,
"specColType":"NORMAL",
"children":[]
}the URL for the REST-API consists of:
collection|dataObject|fileContents)For further information, please read the original IRODS-REST documentation
The “Creator” is the responsible person in the sense of the Urheberrechtsgesetz, taking care that reusing of third party data is legal and in the sense of the DSGVO, that personal data is handled correctly. Even if the “Creator” is not employed at the university any more.
There exists a decision guide if data can be published, sadly only in german.
Different kinds of Licenses exist for various cases, this here is just an incomplete list of the most common Open Access Licenses for the three most common datatypes:
The applicability of CC-BY licenses for Software is not recommended: CC-recommendation and discussion . The same applies for datasets, their publication under a CC-license other than CC0 is doubtful . For other dataset licenses search at Open Definition Licenses Service .
Proprietary file formats should be avoided, since you don’t know if the software to open them still exists in a few years. Try to stick to open standards.
There are a lot more commands. You can look them up in the original documentation: iRODS documentation
iRODS works based a kind of a virtual file system, with its own lingo:
iRODS uses so called ‘Resources’ to archive the collections and data objects. The resources are organized hierarchically. The root is a replication resource, where other resources are added as children. Currently there is a compound resource consisting itself of a cache (unix filesystem) and a universal mass storage system (here: TSM) as archive. The cache has a size of 8TB, once it is fills up, the oldest data objects will be deleted on the cache. If required, they will be fetched back from the archive.
replResc:replication
├── cephfsResc:unixfilesystem
└── compResc:compound
├── netappResc:unixfilesystem
└── tsmResc:univmssHere we show some transfer speed benchmarks:
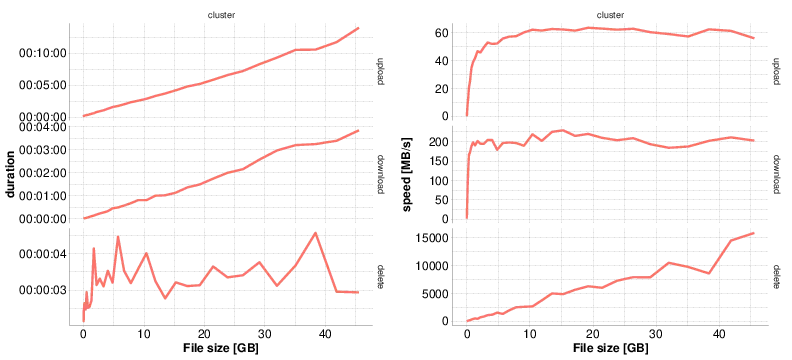
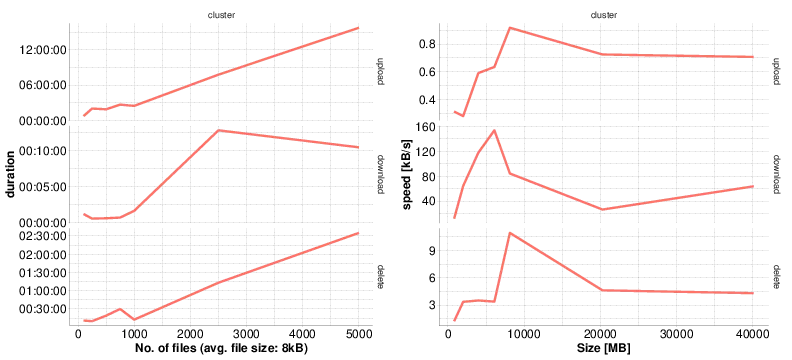
This explains why a directory, resp. collection, consisting of many small files, should be compressed. iRODS works best for files > 5GB.
Every user has a hidden directory ${HOME}/.irods with the file irods_environment.json our the HPC Systems home directory containing the connection information for the iRODS archive. Below you see the information template for irods_environment.json. Do not edit this file.
{
"irods_client_server_negotiation": "request_server_negotiation",
"irods_client_server_policy": "CS_NEG_REQUIRE",
"irods_authentication_scheme": "pam_password",
"irods_host": "irods.zdv.uni-mainz.de",
"irods_port": 1247,
"irods_user_name": "<$USER>",
"irods_zone_name": "zdv",
"irods_encryption_key_size": 32,
"irods_encryption_salt_size": 8,
"irods_encryption_num_hash_rounds": 16,
"irods_encryption_algorithm": "AES-256-CBC"
}