Title here
Summary here
Julia is a high-performance, high-level, dynamic programming language.
Distinctive aspects of Julia’s design include a type system with parametric polymorphism in a dynamic programming language; with multiple dispatch as its core programming paradigm. Julia supports concurrent, (composable) parallel and distributed computing (with or without using MPI and/or the built-in corresponding to “OpenMP-style” threads), and direct calling of C and Fortran libraries without glue code. Julia uses a just-in-time (JIT) compiler that is referred to as “just-ahead-of-time” (JAOT) in the Julia community, as Julia compiles all code (by default) to machine code before running it.
We currently offer the following Julia versions:
JGU HPC Modules
------------------- /cluster/easybuild/broadwell/modules/all -------------------
lang/Julia/1.5.3-linux-x86_64 lang/Julia/1.6.3-linux-x86_64
lang/Julia/1.6.0-linux-x86_64 lang/Julia/1.7.0-linux-x86_64 (D)One can use a specific version with the following command:
module load lang/Julia/1.6.0-linux-x86_64or the current default module with:
module load lang/JuliaPkg is Julia’s built-in package manager that performs tasks such as installing, updating and removing packages.
Initially, you need to load a Julia Module on a MOGON service-node, e.g. with:
module load lang/JuliaFor package installation, we will use the REPL (read-eval-print loop) that comes built-in to the julia executable. Start Julia by using:
juliafrom the command line. Now start the Pkg REPL (Pkg also comes with a REPL) by pressing ], upon entering the Pkg REPL, the command line prompt should like:
(1.6) pkg>We will use the package Dates ( Dates ) to illustrate what the general procedure for installing packages is:
(1.6) pkg> add Datesyou should get an output similar to:
(v1.6) pkg> add Dates
Resolving package versions...
Updating `/gpfs/fs1/home/<username>/.julia/environments/v1.6/Project.toml`
[ade2ca70] + Dates
No Changes to `/gpfs/fs1/home/<username>/.julia/environments/v1.6/Manifest.toml`Let’s check the successful installation: First we display the status of the packages in our standard project:
(v1.6) pkg> statusDepending on which packages you have already installed, you should get an output similar to the following:
(v1.6) pkg> status
Status `/gpfs/fs1/home/<username>/.julia/environments/v1.6/Project.toml`
[6e4b80f9] BenchmarkTools v0.7.0
[052768ef] CUDA v3.0.3
[7a1cc6ca] FFTW v1.3.2
[da04e1cc] MPI v0.17.2
[91a5bcdd] Plots v1.11.2
[d330b81b] PyPlot v2.9.0
[ade2ca70] Dates
[de0858da] Printf
[9a3f8284] RandomThis indicates that Dates has been successfully installed, but let’s check and confirm this with Pkg
(v1.6) pkg> test Dates
Testing Dates
Status `/tmp/jl_cb9pkw/Project.toml`
[ade2ca70] Dates `@stdlib/Dates`
[b77e0a4c] InteractiveUtils `@stdlib/InteractiveUtils`
[de0858da] Printf `@stdlib/Printf`
[8dfed614] Test `@stdlib/Test`
Status `/tmp/jl_cb9pkw/Manifest.toml`
[2a0f44e3] Base64 `@stdlib/Base64`
[ade2ca70] Dates `@stdlib/Dates`
[b77e0a4c] InteractiveUtils `@stdlib/InteractiveUtils`
[56ddb016] Logging `@stdlib/Logging`
[d6f4376e] Markdown `@stdlib/Markdown`
[de0858da] Printf `@stdlib/Printf`
[9a3f8284] Random `@stdlib/Random`
[9e88b42a] Serialization `@stdlib/Serialization`
[8dfed614] Test `@stdlib/Test`
[4ec0a83e] Unicode `@stdlib/Unicode`
Testing Running tests...
[ ... ]
Test Summary: | Pass Total
Conversions to/from numbers | 19 19
Testing Dates tests passedThe installation was sucessful and Dates can now be included in .jl file via the following line:
using DatesYou can now add any packages from the Standard Library to Julia, but please note the following:
Package Dependencies
Some Julia packages require you to load pre-requisite dependencies as modules before you can add the via Pkg.add!
This is also illustrated again by the following examples CUDA and Plots.
In the Pkg REPL you have the following commands available to manage packages:
| Command | Result | Comment |
|---|---|---|
add | Adds a Package | It is possible to ad multiple packages in one command add A B C |
test | Run Tests for a Package | |
build | Explicitly run the build step for a Package | build is automatically run when a package is first installed with add |
rm | Removes Package | Removes only that package in the project. Tto remove a package that only exists as a dependency use rm --manifest DepPackage. Note that this will remove all packages that depend on DepPackage. |
up | Update Package and all dependencies | The Flag --minor updates only the minor version of packages reducingthe risk to break projects. |
status | Print out the status of the project/manifest. |
Installing packages using Pkg adds them to the default project at ~/.julia/environments/<JuliaVersion>. However, it is also possible to work with Environments in Julia and
create own projects
,
precompiling a project
and even
using someone else’s project
Julia’s
CUDA.jl
package is the main entrypoint for programming on NVIDIA GPUs using CUDA. The Julia CUDA stack requires a functional CUDA-setup, which includes the NVIDIA Driver and the corresponding CUDA toolkit. These are either available as module or already integrated into the MOGON GPU nodes. To be able to use CUDA.jl with Julia, you only need to proceed as follows.
Log in to MOGON and load the following modules on a service-node first:
module load system/CUDA/11.0.3-GCC-9.3.0
module load lang/JuliaNow start Julia with the following command
juliaand then change to the Pkg REPL with ], the command line prompt should now look like:
(v1.6) pkg>We are now ready to add CUDA via
(v1.6) pkg> add CUDAYou are now ready to use CUDA.jl with Julia on MOGON. Take a look at our GPU section below for easy approach to CUDA.jl on MOGON.
Plots.jl
is a visualization interface and toolset for powerful visualizations in Julia. Here we explain how to add the Plots.jl package to Julia and set up the backend PyPlot.
Log in to MOGON and load the following modules on a service-node first:
module load lang/SciPy-bundle/2020.03-foss-2020a-Python-3.8.2
module load vis/matplotlib/3.2.1-foss-2020a-Python-3.8.2
module load lang/JuliaOpen Julia by executing the following command after the modules have been successfully loaded
julianow enter the Pkg REPL by pressing ], the command line prompt should look like:
(v1.6) pkg>First, the actual packages are added and then the backend is configured. Install Plots.jl with:
(v1.6) pkg> add Plotsnow set the backend to pyplot with:
(v1.6) pkg> add PyPlotAfterwards, test the successful installation with:
(v1.6) pkg> test Plotsand
(v1.6) pkg> test PyPlotAn overview of available packages for Julia can be found in the Julia Documentation and JuliaLang Github Repo . The most noteworthy packages are (aka. you will probably install them at some point):
| Package | Comment |
|---|---|
| Random | |
| CUDA | |
| LinearAlgebra | |
| Printf | |
| MPI | |
| BenchmarkTools | |
| FFTW |
println("Hello MOGON!")#!/bin/bash
#SBATCH --partition=smp
#SBATCH --account=<mogon-project>
#SBATCH --time=0-00:01:00
#SBATCH --mem=512 #0.5GB
#SBATCH --ntasks=1
#SBATCH --job-name=julia_serial_example
#SBATCH --output=%x_%j.out
#SBATCH --error=%x_%j.err
module purge
module load lang/Julia
julia hello_mogon.jlcat julia_serial_example_*.outHello MOGON!Julia offers two main possibilities for parallel computing: A multi-threading based parallelism, which basically is a shared memory parallelism and distributed Processing, which parallelizes code across different Julia processes.
The number of execution threads is controlled either by using the
-t/--threadscommand line argument or by using theJULIA_NUM_THREADSenvironment variable. When both are specified, then-t/--threadstakes precedence.Julia Documentation, Multi-Threading
Therefore, to start Julia with four threads, you must execute the following command:
julia --threads 4But let’s explore the basics of Julia’s multi-threading capabilities with an example:
Threads.@threads for i=1:20
println(Hello MOGON! The Number of iteration is $i from Thread $(Threads.threadid())/$(Threads.nthreads()))
end #!/bin/bash
#SBATCH --partition=smp
#SBATCH --account=<mogon-project>
#SBATCH --time=0-00:02:00
#SBATCH --mem-per-cpu=1024 #1GB
#SBATCH --nodes=1
#SBATCH --ntasks-per-node=1
#SBATCH --cpus-per-task=6
#SBATCH --job-name=smp_julia
#SBATCH --output=%x_%j.out
#SBATCH --error=%x_%j.err
module purge
module load lang/Julia
julia --threads $SLURM_CPUS_PER_TASK hello_mogon_smp.jlOnce the job is finished, you can display the result with the following command:
cat smp_julia_*The output should be similar to the following lines:
Hello MOGON! The Number of iteration is 5 from Thread 2/6
Hello MOGON! The Number of iteration is 9 from Thread 3/6
Hello MOGON! The Number of iteration is 15 from Thread 5/6
Hello MOGON! The Number of iteration is 10 from Thread 3/6
Hello MOGON! The Number of iteration is 11 from Thread 3/6
Hello MOGON! The Number of iteration is 12 from Thread 4/6
Hello MOGON! The Number of iteration is 16 from Thread 5/6
Hello MOGON! The Number of iteration is 17 from Thread 5/6
Hello MOGON! The Number of iteration is 6 from Thread 2/6
Hello MOGON! The Number of iteration is 13 from Thread 4/6
Hello MOGON! The Number of iteration is 7 from Thread 2/6
Hello MOGON! The Number of iteration is 14 from Thread 4/6
Hello MOGON! The Number of iteration is 1 from Thread 1/6
Hello MOGON! The Number of iteration is 8 from Thread 2/6
Hello MOGON! The Number of iteration is 2 from Thread 1/6
Hello MOGON! The Number of iteration is 3 from Thread 1/6
Hello MOGON! The Number of iteration is 18 from Thread 6/6
Hello MOGON! The Number of iteration is 4 from Thread 1/6
Hello MOGON! The Number of iteration is 19 from Thread 6/6
Hello MOGON! The Number of iteration is 20 from Thread 6/6Starting with
julia -p nprovidesnworker processes on the local machine. Generally it makes sense fornto equal the number of CPU threads (logical cores) on the machine. Note that the-pargument implicitly loads module Distributed Julia Documentation,
@everywhere begin
using LinearAlgebra
a = zeros(200,200);
end
slurm_cores = parse(Int, ENV["SLURM_CPUS_PER_TASK"])
slurm_tasks = parse(Int, ENV["SLURM_NTASKS"])
println("Number of requested Slurm Tasks is: ", slurm_tasks)
println("Number of requested Slurm CPUs per Task is: ", slurm_cores)
println("Number of available Julia Processes: ", nprocs())
println("Number of available Julia Worker Processes: ", nworkers())
calctime = @elapsed @sync @distributed for i1:200
a[i] = maximum(abs.(eigvals(rand(500,500))))
end
println("With ", slurm_cores, " CPUs per Task the calculation took ", calctime, " seconds.")#SBATCH --partition=smp
#SBATCH --account=<mogon-project>
#SBATCH --time=0-00:03:00
#SBATCH --mem-per-cpu=4096 #4GB
#SBATCH --nodes=1
#SBATCH --ntasks-per-node=1
#SBATCH --cpus-per-task=2
#SBATCH --job-name=dist_julia
#SBATCH --output=%x_%j.out
#SBATCH --error=%x_%j.err
module purge
module load lang/Julia
julia --procs $SLURM_CPUS_PER_TASK parallel_julia_example.jlcat dist_julia*.out[ ... ]
With 2 CPUs per Task the calculation took 34.029345377 seconds.| CPUs per Task | Runtime (s) |
|---|---|
| 2 | 34.03 |
| 4 | 19.27 |
| 6 | 14.58 |
| 8 | 12.02 |
Of course, you can also use MPI with Julia on MOGON. This requires you to first carry out the following setup for Julia and the MPI interface MPI.jl.
First, Julia must be configured for the use of MPI. For this purpose the MPI Wrapper for Julia is used. Log in to one ouf our Service-Nodes and then load Julia and the desired MPI module via:
module load mpi/OpenMPI/4.0.3-GCC-9.3.0
module load lang/JuliaNext, you need to build the MPI package for Julia with Pkg:
julia -e 'ENV["JULIA_MPI_BINARY"]="system"; using Pkg; Pkg.add("MPI"); Pkg.build("MPI", verbose=true)'The output should be similar to the following if installation and build was successful:
[ ... ]
[ Info: using system MPI ] 0/1
┌ Info: Using implementation
│ libmpi = "libmpi"
│ mpiexec_cmd = "mpiexec"
└ MPI_LIBRARY_VERSION_STRING = "Open MPI v4.0.3, package: Open MPI Distribution, ident: 4.0.3, repo rev: v4.0.3, Mar 03, 2020"
┌ Info: MPI implementation detected
│ impl = OpenMPI::MPIImpl 2
│ version = v"4.0.3"
└ abi = "OpenMPI"
1 dependency successfully precompiled in 3 seconds (140 already precompiled, 1 skipped during auto due to previous errors)Now that MPI and Julia have been set up correctly, we can proceed to the example.
using MPI
MPI.Init()
comm = MPI.COMM_WORLD
my_rank = MPI.Comm_rank(comm)
comm_size = MPI.Comm_size(comm)
println("Hello MOGON! I am Rank ", my_rank, " of ", comm_size, " on ", gethostname())
MPI.Finalize()#!/bin/bash
#SBATCH --partition=parallel
#SBATCH --account=<mogon-project>
#SBATCH --time=0-00:02:00
#SBATCH --mem-per-cpu=2048 #2GB
#SBATCH --nodes=2
#SBATCH --ntasks-per-node=8
#SBATCH --job-name=mpi_julia
#SBATCH --output=%x_%j.out
#SBATCH --error=%x_%j.err
module purge
module load mpi/OpenMPI/4.0.5-GCC-10.2.0
module load lang/Julia
export JULIA_MPI_PATH=$EBROOTOPENMPI
srun julia -- hello_mogon_mpi.jlcat mpi_julia_*.outHello MOGON! I am Rank 9 of 16 on z0278.mogon
Hello MOGON! I am Rank 2 of 16 on z0277.mogon
Hello MOGON! I am Rank 11 of 16 on z0278.mogon
Hello MOGON! I am Rank 12 of 16 on z0278.mogon
Hello MOGON! I am Rank 15 of 16 on z0278.mogon
Hello MOGON! I am Rank 10 of 16 on z0278.mogon
Hello MOGON! I am Rank 13 of 16 on z0278.mogon
Hello MOGON! I am Rank 8 of 16 on z0278.mogon
Hello MOGON! I am Rank 14 of 16 on z0278.mogon
Hello MOGON! I am Rank 1 of 16 on z0277.mogon
Hello MOGON! I am Rank 3 of 16 on z0277.mogon
Hello MOGON! I am Rank 5 of 16 on z0277.mogon
Hello MOGON! I am Rank 4 of 16 on z0277.mogon
Hello MOGON! I am Rank 0 of 16 on z0277.mogon
Hello MOGON! I am Rank 6 of 16 on z0277.mogon
Hello MOGON! I am Rank 7 of 16 on z0277.mogonBefore you start parallelising with Julia on MOGON GPUs, you need to prepare your Julia environemnt for the usage pf GPUs, as we explaind earlier in the Article about CUDA.jl. After successfully setting up CUDA.jl, you can directly start utilising the advantages of GPUs. We have given some examples below to make it easier for you to start using Julia on MOGON GPUs and to somewhat reflect the advantages of GPUs.
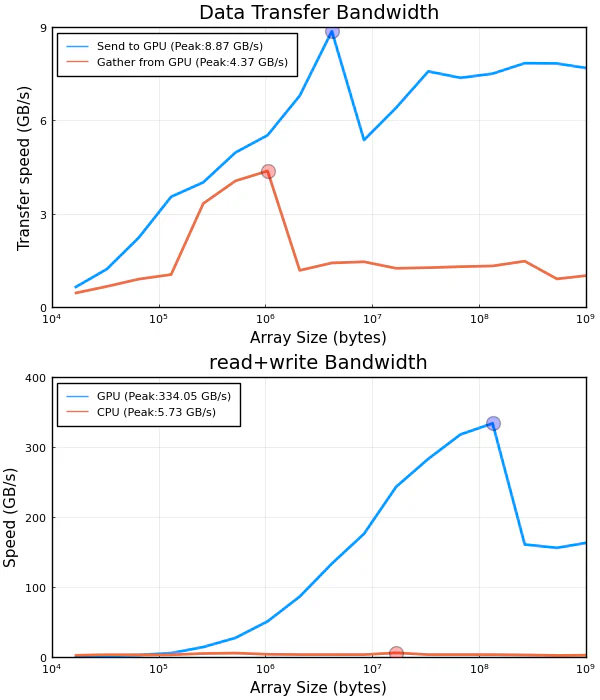
The test estimates how fast data can be sent to and read from the GPU. Since the GPU is plugged into a PCI bus, this largely depends on the speed of the PCI bus as well as many other factors. However, there is also some overhead included in the measurements, in particular the overhead for function calls and array allocation time. However, since these are present in any “real” use of the GPU, it is reasonable to include them. Memory is allocated and data is sent to the GPU using Julia’s CUDA.jl package. Memory is allocated and data is transferred back to CPU memory using Julia’s native Array() function.
The theoretical bandwidth per lane for PCIe 3.0 is $0.985 GB/s$. For the GTX 1080Ti (PCIe3 x16) used in our MOGON GPU nodes the 16-lane slot could theoretical give $15.754 GB/s$[^1].
using LinearAlgebra
using Plots
pyplot()
using BenchmarkTools
using Printf
using CUDA
using Random
sizes = 2 .^ (14:30);
timeSend = Array{Float64}(undef, length(sizes));
timeGather = Array{Float64}(undef, length(sizes));
sendBandwidth = Array{Float64}(undef, length(sizes));
gatherBandwidth = Array{Float64}(undef, length(sizes));
memoryTimesCPU = Array{Float64}(undef, length(sizes));
memoryTimesGPU = Array{Float64}(undef, length(sizes));
memoryBandwidthGPU = Array{Float64}(undef, length(sizes));
memoryBandwidthCPU = Array{Float64}(undef, length(sizes));
for i = 1:length(sizes)
GC.gc(true)
numElements = convert(Int64, sizes[i] / 8);
cpuData = rand(0:9, (numElements, 1));
gpuData = CuArray{Float64}(rand(0:9, (numElements, 1)));
# Time to GPU
timeSend[i] = CUDA.@elapsed CuArray(cpuData);
# Time from GPU
timeGather[i] = CUDA.@elapsed Array(gpuData);
sendBandwidth[i] = (sizes[i] / timeSend[i] / 1e9);
gatherBandwidth[i] = (sizes[i] / timeGather[i] / 1e9);
memoryTimesGPU[i] = CUDA.@elapsed CUDA.@sync gpuData .+ 1;
memoryBandwidthGPU[i] = 2*(sizes[i] / memoryTimesGPU[i] / 1e9);
memoryTimesCPU[i] = @elapsed cpuData .+ 1;
memoryBandwidthCPU[i] = 2*(sizes[i] / memoryTimesCPU[i] / 1e9);
end
@printf("Achieved peak send speed of %.1f GB/s \n", maximum(sendBandwidth))
@printf("Achieved peak gather speed of %.1f GB/s \n", maximum(gatherBandwidth))
@printf("Achieved peak read+write speed on the GPU: %.1f GB/s \n",maximum(memoryBandwidthGPU))
@printf("Achieved peak read+write speed on the CPU: %.1f GB/s \n",maximum(memoryBandwidthCPU))
p1 = plot(
sizes,
sendBandwidth,
lw = 2,
legend = :topleft,
xaxis = ("Array Size (bytes)", :log10),
xlims = (10^4, 10^9),
frame = true,
label = string("Send to GPU (Peak:",round(maximum(sendBandwidth),digits2)," GB/s)");
);
plot!(p1, sizes, gatherBandwidth, lw = 2, label string("Gather from GPU (Peak:",round(maximum(gatherBandwidth),digits=2)," GB/s)"));
plot!(p1,yaxis = ("Transfer speed (GB/s)"));
plot!(p1,title = ("Data Transfer Bandwidth"));
plot!(p1,minorxgrid = true, ylims :round);
scatter!(
[sizes[argmax(sendBandwidth)], sizes[argmax(gatherBandwidth)]],
[maximum(sendBandwidth), maximum(gatherBandwidth)],
label = "",
marker = (10, 0.3, [:blue, :red]),
);
p2 = plot(
sizes,
memoryBandwidthGPU,
lw = 2,
legend = :topleft,
xaxis = ("Array Size (bytes)", :log10),
xlims = (10^4, 10^9),
frame = true,
label = string("GPU (Peak:",round(maximum(memoryBandwidthGPU),digits2)," GB/s)");
);
plot!(p2,sizes, memoryBandwidthCPU, lw = 2, label string("CPU (Peak:",round(maximum(memoryBandwidthCPU),digits=2)," GB/s)"));
plot!(p2,yaxis = ("Speed (GB/s)"));
plot!(p2,title = ("read+write Bandwidth"));
plot!(p2,minorxgrid = true, ylims :round);
scatter!(
[sizes[argmax(memoryBandwidthGPU)], sizes[argmax(memoryBandwidthCPU)]],
[maximum(memoryBandwidthGPU), maximum(memoryBandwidthCPU)],
label = "",
marker = (10, 0.3, [:blue, :red]),
);
p3 = plot(p1,p2, layout grid(2, 1, widths=[1]), size(600,700));
savefig(p3, "gpu_rw_perf_result.png")The job script is pretty ordinary. In this example, we use only one GPU and start Julia with four threads. To do this, we request one process with four cpus for multithreading:
#!/bin/bash
#SBATCH --account=<mogon-project>
#SBATCH --job-name=gpu_rw
#SBATCH --output=%x_%j.out
#SBATCH --error=%x_%j.err
#SBATCH --partition=m2_gpu
#SBATCH --gres=gpu:1
#SBATCH --time=0-00:10:00
#SBATCH --mem=11550
#SBATCH --ntasks=1
#SBATCH --cpus-per-task=4
module purge
module load lang/SciPy-bundle/2020.03-foss-2020a-Python-3.8.2
module load vis/matplotlib/3.2.1-foss-2020a-Python-3.8.2
module load system/CUDA/11.0.3-GCC-9.3.0
module load lang/Julia
julia --threads 4 gpu_rw.jlThe job is submitted with the following command
sbatch julia_gpu_rw_job.slurmThe job will be finished after a few minutes, you can view the output as follows:
cat gpu_rw*.outThe output should be similar to the following lines:
Achieved peak send speed of 8.9 GB/s
Achieved peak gather speed of 4.4 GB/s
Achieved peak read+write speed on the GPU: 334.0 GB/s
Achieved peak read+write speed on the CPU: 5.7 GB/sThe Julia script also generates a plot, which we would like to show here:
You might be familiar with this example if you stumbled upon our MATLAB article or read it on purpose. At this point we would simply like to restate what we originally took from the MATLAB Help Center :
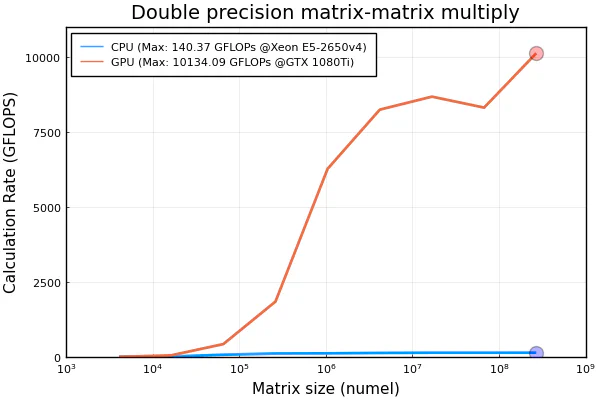
For operations where the number of floating-point computations performed per element read from or written to memory is high, the memory speed is much less important. In this case the number and speed of the floating-point units is the limiting factor. These operations are said to have high “computational density”.
A good test of computational performance is a matrix-matrix multiply. For multiplying two $N times N$ matrices, the total number of floating-point calculations is $$ FLOPS(N) = 2N^3 - N^2 $$
Two input matrices are read and one resulting matrix is written, for a total of $3N^2$ elements read or written. This gives a computational density of $(2N - 1)/3$ FLOP/element. Contrast this with plus as used above, which has a computational density of $1/2$ FLOP/element.
MATLAB Help Center, Measuring GPU Performance
The difference to our MATLAB article is of course the adaptation to native Julia code. But even so, we have made a few alterations due to the use of the Julia language. When defining vectors or arrays, we have purposely chosen Float32, since GPUs are faster when working with Float32 than with Float64. In addition CuArrys are by default Float32, as well as functions like CUDA.rand or CUDA.zeros.
using LinearAlgebra
using Plots
pyplot()
using BenchmarkTools
using Printf
using CUDA
sizes = 2 .^ (12:2:28);
N = convert(Array{Int128,1}, sqrt.(sizes))
timeCPU = Vector{Float32}(undef, length(sizes));
timeGPU = Vector{Float32}(undef, length(sizes));
for i = 1:length(sizes)
# First on the CPU
An = rand(Float32, N[i], N[i])
Bn = rand(Float32, N[i], N[i])
timeCPU[i] = @elapsed An * Bn
GC.gc(true)
# Now on the GPU
Ac = CUDA.rand(N[i], N[i])
Bc = CUDA.rand(N[i], N[i])
timeGPU[i] = CUDA.@elapsed Ac * Bc
GC.gc(true)
CUDA.reclaim()
end
gflopsCPU = (2 * N .^ 3 - N .^ 2) ./ timeCPU / 1e9;
gflopsGPU = (2 * N .^ 3 - N .^ 2) ./ timeGPU / 1e9;
@printf(
"Achieved peak calculation rates of %.1f GFLOPS on CPU, %.1f GFLOPS on GPU ",
maximum(gflopsCPU),
maximum(gflopsGPU)
)
plot(
sizes,
gflopsCPU,
lw = 2,
legend = :topleft,
xaxis = ("Matrix size (numel)", :log10),
xlims = (10^3, 10^9),
frame = true,
label = string(
"CPU (Max: ",
round(maximum(gflopsCPU), digits = 2),
" GFLOPs @Xeon E5-2650v4)",
),
);
plot!(
sizes,
gflopsGPU,
lw = 2,
label = string(
"GPU (Max: ",
round(maximum(gflopsGPU), digits = 2),
" GFLOPs @GTX 1080Ti)",
),
);
plot!(yaxis = ("Calculation Rate (GFLOPS)"));
plot!(title = ("Double precision matrix-matrix multiply"));
plot!(minorxgrid = true, ylims :round);
scatter!(
[sizes[argmax(gflopsCPU)], sizes[argmax(gflopsGPU)]],
[maximum(gflopsCPU), maximum(gflopsGPU)],
label = "",
marker = (10, 0.3, [:blue, :red]),
);
savefig("gpu_perf_result.png")The job script is quite ordinary. In this example, we only use one GPU and start Julia with four threads. For this we request one process with four CPUs for multithreading.
#!/bin/bash
#SBATCH --account=<mogon-project>
#SBATCH --job-name=gpu_perf
#SBATCH --output=%x_%j.out
#SBATCH --error=%x_%j.err
#SBATCH --partition=m2_gpu
#SBATCH --gres=gpu:1
#SBATCH --time=0-00:10:00
#SBATCH --mem=8192
#SBATCH --ntasks=1
#SBATCH --cpus-per-task=4
module purge
module load lang/SciPy-bundle/2020.03-foss-2020a-Python-3.8.2
module load vis/matplotlib/3.2.1-foss-2020a-Python-3.8.2
module load system/CUDA/11.0.3-GCC-9.3.0
module load lang/Julia
julia --threads 4 gpu_perf.jlYou can submit the job by simply executing:
sbatch julia_gpu_perf_job.slurmThe job will be completed after acouple of minutes and you can view the output with:
cat gpu_perf*.outThe Output should resemble the following lines:
Achieved peak calculation rates of 140.4 GFLOPS on CPU, 10134.1 GFLOPS on GPUThe graphic generated in the script is shown below: